Lambda架构
Lambda架构和Kappa架构之常用的大数据处理架构
星期四, 六月 3rd, 2021 | 大数据 | 没有评论
首先我们来看一个典型的互联网大数据平台的架构,如下图所示:
111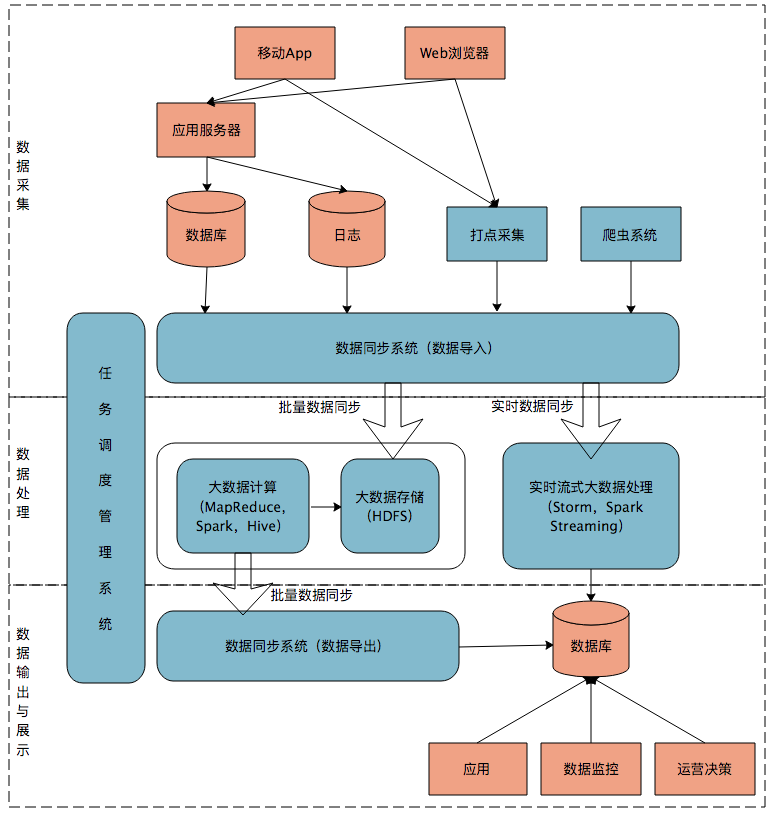
在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使用开源大数据产品或者自己开发相关大数据组件。
你可以看到,大数据平台由上到下,可分为三个部分:数据采集、数据处理、数据输出与展示。
数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。数据库同步通常用 Sqoop,日志同步可以选择 Flume,打点采集的数据经过格式化转换后通过 Kafka 等消息队列进行传递。
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以使用了,而日志和爬虫产生的数据就需要进行大量的清洗、转化处理才能有效使用。
数据处理
这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在 HDFS。MapReduce、Hive、Spark 等计算任务读取 HDFS 上的数据进行计算,再将计算结果写入 HDFS。
MapReduce、Hive、Spark 等进行的计算处理被称作是离线计算,HDFS 存储的数据被称为离线数据。在大数据系统上进行的离线计算通常针对(某一方面的)全体数据,比如针对历史上所有订单进行商品的关联性挖掘,这时候数据规模非常大,需要较长的运行时间,这类计算就是离线计算。
除了离线计算,还有一些场景,数据规模也比较大,但是要求处理的时间却比较短。比如淘宝要统计每秒产生的订单数,以便进行监控和宣传。这种场景被称为大数据流式计算,通常用 Storm、Spark Steaming 等流式大数据引擎来完成,可以在秒级甚至毫秒级时间内完成计算。
数据输出与展示
大数据计算产生的数据还是写入到 HDFS 中,但应用程序不可能到 HDFS 中读取数据,所以必须要将 HDFS 中的数据导出到数据库中。数据同步导出相对比较容易,计算产生的数据都比较规范,稍作处理就可以用 Sqoop 之类的系统导出到数据库。

Search
相关文章
热门文章
最新文章
文章分类
- ajax (10)
- algorithm-learn (3)
- Android (6)
- as (3)
- computer (85)
- Database (30)
- disucz (4)
- enterprise (1)
- erlang (2)
- flash (5)
- golang (3)
- html5 (18)
- ios (4)
- JAVA-and-J2EE (186)
- linux (143)
- mac (10)
- movie-music (11)
- pagemaker (36)
- php (50)
- spring-boot (2)
- Synology群晖 (2)
- Uncategorized (6)
- unity (1)
- webgame (15)
- wordpress (33)
- work-other (2)
- 低代码 (1)
- 体味生活 (40)
- 前端 (21)
- 大数据 (8)
- 游戏开发 (9)
- 爱上海 (19)
- 读书 (4)
- 软件 (3)