Database
mysql5.5版本数据类型、索引、查询的优化技巧(5.7版本适用)
星期三, 四月 13th, 2022 | Database, JAVA-and-J2EE | 没有评论
mysql5.5版本数据类型、索引、查询的优化技巧(5.7版本适用)
总结一些MySQL的常见使用技巧,以供没有DBA的团队参考。以下内容以MySQL5.5为准,如无特殊说明,存储引擎以InnoDB为准。
最新版8.0已经优化很多了,比如尽量使用子查询等,不断实践才能验证,做好数据压测即可检测.
本文大纲:
MySQL的特点
数据类型优化
索引优化
查询优化
一、MySQL的特点
了解MySQL的特点有助于更好的使用MySQL,MySQL和其它常见数据库最大的不同在于存在存储引擎这个概念,存储引擎负责存储和读取数据。不同的存储引擎具有不同的特点,用户可以根据业务的特点选择适合的存储引擎,甚至是开发一个新的引擎。
MySQL的逻辑架构大致如下:
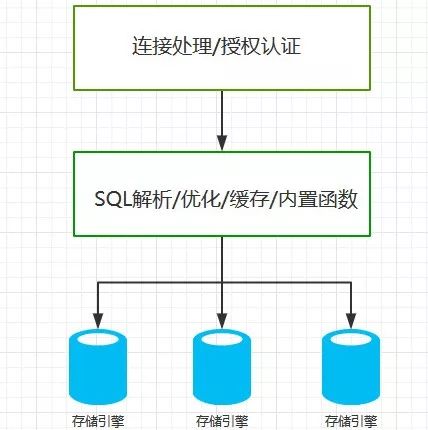
MySQL默认的存储引擎是InnoDB,该存储引擎的主要特点是:
支持事务处理
支持行级锁
数据存储在表空间中,表空间由一些列数据文件组成
采用MVVC(多版本并发控制)机制实现高并发
表基于主键的聚簇索引建立
支持热备份
其它常见存储引擎特点概述:
MyISAM:老版本MySQL的默认引擎,不支持事务和行级锁,开发者可以手动控制表锁;支持全文索引;崩溃后无法安全恢复;支持压缩表,压缩表数据不可修改,但占用空间较少,可以提高查询性能
Archive:只支持Insert和Select,批量插入很快,通过全表扫描查询数据
SCV:把一个SCV文件当做一个表处理
Memory:数据存储在内存中
还有很多,不再一一列举。
二、数据类型优化
选择数据类型的原则:
选择占用空间小的数据类型
选择简单的类型
避免不必要的可空列
占用空间小的类型更节省硬件资源,如磁盘、内存和CPU。
尽量使用简单的类型,如能用int就不用char,因为后者的排序涉及到字符集的选择,比使用int复杂。
可空列使用更多的存储空间,如果在可空列上创建索引,MySQL需要额外的字节做记录。
创建表时,默认都是可空,容易被开发者忽视,最好是手动改为不可空,如果要存储的数据确实不会有空值的话。
1、整型类型
整型类型包括:
tinyint SMALLINT mediumint INT BIGINT |
它们分别使用8、16、24、32和64位存储数字,它们可以表示−2n−1−2n−1到2n−1−12n−1−1范围的数字,前面可以加unsigned修饰,这样可以让正数的可表示范围提高1倍,但是无法表示负数。
另外,为整型指定长度没什么卵用,数据类型定下来,长度也就相应定下来了。
2、小数类型
FLOAT DOUBLE DECIMAL |
float和double就是通常意义上的float和double,前者使用32位存储数据,后者使用64位存储数据,和整型一样,为它们指定长度没什么卵用。
decimal类型比较复杂,支持精确计算,占用的空间也大,decimal使用每4个字节表示9个数字,如decimal(18,9)表示数字长度是18,其中小数位9个数字,整数部分9个数字,加上小数点本身,共占用9个字节。
考虑到decimal占用空间较多,以及精度计算很复杂,数据量大的时候可以考虑用bigint代替之,可以在持久化和读取前对真实数据进行一些缩放操作。
3、字符串类型
VARCHAR CHAR varbinary BINARY BLOB text |
枚举
varchar类型数据实际占用空间等于字符串的长度加上1个或2个用来记录字符串长度的字节(当row-format没有被设置为fixed时),varchar很节省空间。当表中某列字符串类型的数据长度差别较大时适合使用varchar。
char的实际占用空间是固定的,当表中字符串数据的长度相差无几或很短时适合使用chart类型。
与varchar和char对应的有varbinary和binary,后者存储的是二进制字符串,和前者相比,后者大小写敏感,不用考虑编码方式,执行比较操作时更快。
需要注意的是:虽然varchar(5)和varchar(200)在存储“hello”这个字符串时使用相同的存储空间,但并不意味着将varchar的长度设置太大不会影响性能,实际上,MySQL的某些内部计算,比如创建内存临时表时(某些查询会导致MySQL自动创建临时表),会分配固定大小的空间存放数据。
blob使用二进制字符串保存大文本,text使用字符保存大文本,InnoDB会使用专门的外部存储区来存放此类数据,数据行内仅存放指向他们的指针,此类数据不宜创建索引(要创建也只能正对字符串前缀创建),不过也不会有人这么干。
如果某列字符串大量重复且内容有限,可使用枚举代替,MySQL处理枚举时维护了一个“数字-字符串”表,使用枚举可以减少很多存储空间。
4、时间类型
YEAR DATE TIME datetime TIMESTAMP |
datetime存储范围是1001到9999,精确到秒。
timestamp存储1970年1月1日午夜以来的秒数,可以表示到2038年。占用4个字节,是datetime占用空间的一半。timestamp表示的时间和时区有关,另外timestamp列还有个特性,执行insert或update语句时,MySQL会自动更新第一个类型为timestamp的列的数据为当前时间。
很多表中都有设计有一列叫做UpdateTime,这个列使用timestamp倒是挺合适的,会自动更新,前提是系统不会使用到2038年。
5、主键类型的选择
尽可能使用整型,整型占用空间少,还可以设置为自动增长。尤其别使用GUID,MD5等哈希值字符串作为主键,这类字符串随机性很大,由于InnoDB主键默认是聚簇索引列,所以导致数据存储太分散。
另外,InnoDB的二级索引列中默认包含主键列,如果主键太长,也会使得二级索引很占空间。
6、特殊类型的数据
存储IP最好使用32位无符号整型,MySQL提供了函数inet_aton()和inet_ntoa()进行IP地址的数字表示和字符串表示之间的转换。
三、索引优化
InnoDB使用B+树实现索引,举个例子,假设有个People,建表语句如下
CREATE TABLE `people` ( `Id` INT(11) NOT NULL AUTO_INCREMENT, `Name` VARCHAR(5) NOT NULL, `Age` tinyint(4) NOT NULL, `Number` CHAR(5) NOT NULL COMMENT '编号', PRIMARY KEY (`Id`), KEY `i_name_age_number` (`Name`,`Age`,`Number`) ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8; |
插入数据:
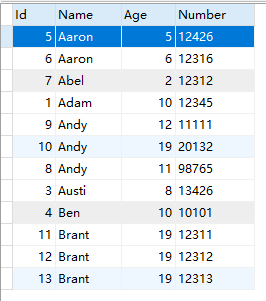
它的索引结构大致是这样的:
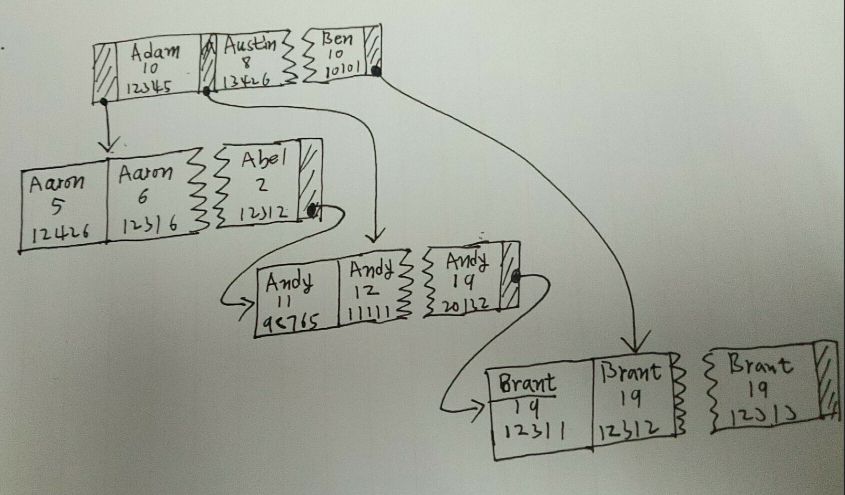
也就是说,索引列的顺序很重要,如果两行数据的Name列相同,则用Age列比较大小,如果Age列相同,则用Number列比较大小。先用第一列排序,然后是第二列,最后是第三列。
查询的使用应该尽量从左往右匹配,另外,如果左边列范围查找,右边列无法使用索引;还有就是不能隔列查询,否则后面的索引也无法使用到。如以下几个SQL是正面范例:
SELECT * FROM people WHERE Name ='Abel' AND Age = 2 AND NUMBER = 12312 SELECT * FROM people WHERE Name ='Abel' SELECT * FROM people WHERE Name LIKE 'Abel%' SELECT * FROM people WHERE Name = 'Andy' AND Age BETWEEN 11 AND 20 SELECT * FROM people ORDER BY NAME SELECT * FROM people ORDER BY NAME, Age SELECT * FROM people GROUP BY Name |
以下几个SQL是反面范例:
SELECT * FROM people WHERE Age = 2 SELECT * FROM people WHERE NAME LIKE '%B' SELECT * FROM people WHERE age = 2 SELECT * FROM people WHERE NAME = 'ABC' AND NUMBER = 3 SELECT * FROM people WHERE NAME LIKE 'B%' AND age = 22 |
1、一个使用Hash值创建索引的技巧
如果表中有一列存储较长字符串,假设名字为URL,在此列上创建的索引比较大,有个办法可以缓解:创建URL字符串的数字哈希值的索引。再新建一个字段,比如叫做URL_CRC,专门放置URL的哈希值,然后给这个字段创建索引,查询时这样写:
SELECT * FROM t WHERE URL_CRC = 387695885 AND URL = 'www.baidu.com' |
如果数据量比较多,为防止哈希冲突,可自定义哈希函数,或用MD5函数返回值的一部分作为哈希值:
SELECT CONV(RIGHT(MD5('www.baidu.com'),16), 16, 10) |
2、前缀索引
如果字符串列存储的数据较长,创建的索引也很大,这时可以使用前缀索引,即:只针对字符串前几个字符做索引,这样可以缩短索引的大小,不过,显然,此类索引在执行order by和group by时不起作用。
创建前缀索引时选择前缀长度很重要,在不破坏原来数据分布的情况下尽可能选择较短的前缀。举个例子,如果如果大部分字符串是以”abc”开头,那么如果限定前缀索引长度为4,索引值会包含太多的重复的”abcX”。
3、多列索引
上面提到的“People”上创建的索引即为多列索引,多列索引往往比多个单列索引更好。
对多个索引进行and查询时,应该创建多列索引,而不是多个单列索引。
可以试试这样写的效果:
SELECT * FROM t WHERE f1 = 'v1' AND f2 <> 'v2' UNION ALL SELECT * FROM t WHERE f2 = 'v2' AND f1 <> 'v1' |
多列索引的顺序很重要,通常,不考虑排序和分组查询时,应该把选择性(选择性是指某表索引列不同数据的个数/总行数。选择性高意味着重复数据少)大的列放到前面。但也有例外,如果能确认某些查询是频繁执行的,则应该优先照顾这些查询的选择性,比如,如果上面的People表中Name的选择性大于Age,查询语句应该这样写:
SELECT * FROM people WHERE name = 'xxx' AND age = xx |
Name列放了索引中的左侧比较合适,但是如果某个SQL执行的评率最高,比如:
SELECT * FROM people WHERE name = 'xxx' AND age = 20 |
当age=20的记录在数据库中非常少时,反而把age放到索引列的左端效率更高。把age放了索引左端可能对其它age不等于20的查询来说不公平,如果不能确定age=20是最非常频繁的查询条件,还是要综合考虑,把name放了左侧合适。
4、聚簇索引
聚簇索引是一种数据存储结构,InnoDB在主键的索引的叶子节点中直接保存了数据行,而不是像二级索引那样只是保存了索引列的值和所指向行的主键值。由于这个特性,一个表只能有一个聚簇索引。如果一个表没有定义主键也没有定义具有唯一索引的列,那么InnoDB会生成一个隐藏列,并且在此列设为聚簇索引列。
5、覆盖索引
简单地说,某些查询只需要查询索引列,那么就不用再根据索引B树节点记录的主键ID进行二次查询了。
6、重复索引和冗余索引
如果重复在某列创建索引,并不会带来任何好处,只有坏处,应该尽量避免。比如给主键创建唯一索引和普通索引就是多于的,因为InnoDB的主键默认就是聚簇索引了。
冗余索引和重复索引不同,比如某个索引是(A,B),另一个索引是(A),这叫冗余索引,前者可以代替后者,后者不可以代替前者的作用。但是(A,B)和(B)以及(A,B)和(B,A)不算冗余索引,起作用谁也代替不了谁。
如果一个表中已经存在索引(A),现在又想创建索引(A,B),那么只需扩展就的索引就可以,没有必要创建新的索引。需要注意的是如果已经存在索引(A),那么也没有必要在创建索引(A,ID),其中ID指主键,因为索引A默认已经包含了主键了,也算是冗余主键。
但是,有时候,冗余索引也是可取的,假设已经存在索引(A),将其扩展为(A,B)后,因为B列是一个很长的类型,导致用A单独查询时没有以前快了,这时可以考虑新创建索引(A,B)。
7、不使用的索引
不使用的索引徒然增加insert、update和delete的效率,应该及时删除。
8、索引使用总结
索引的三星原则:
索引将查询相关的记录按顺序放在一起则得一星
索引中的数据顺序和查询结果的排序一致则得一星
索引中包含了查询所需要的全部列则得一星
第一个条原则的意思是where条件中查询的顺序和索引是一致的,就是前面说的从左到右使用索引。
索引不是万能的,当数据量巨大时,维护索引本身也是耗费性能的,应该考虑分区分表存储。
四、查询优化
› Continue reading
centos7开启sshd多端口登录及修改端口
星期三, 十二月 4th, 2019 | Database, linux | 3 Comments
0.不知道怎么回事 一台国外的机器的ssh的22端口,时常无法ssh连接,因此多加个端口来备用
1.编辑配置文件打开Port=22 或者修改此端口
vi /etc/ssh/sshd_config
Port 22
Port 1022
2.重启sshd服务
systemctl restart sshd
3.查看服务启动情况
netstat -lntp |
4.防火墙放行
iptables -A INPUT -p tcp --dport 1022 -j ACCEPT |
5.使用xshell等连接即可
可以同时使用22及1022的端口进行sshd连接服务器了
springboot 使用druid连接池及使用原JDBCTemplate配置
星期日, 六月 30th, 2019 | Database, JAVA-and-J2EE | 没有评论
0.springboot 版本说明2.1.4.RELEASE
1.起因是部门架构部说druid在高并发下和以前的框架集成包有冲突
会造成连接池无法缓存,连接数暴涨,达到最大连接数,从而造成服务异常
2.我没有实际测试,也不好直接下结论,姑且把常用的spring boot 集成的druid配置如下:
<dependency> <groupid>org.springframework</groupid> <artifactid>spring-jdbc</artifactid> </dependency> <dependency> <groupid>com.alibaba</groupid> <artifactid>druid-spring-boot-starter</artifactid> <version>1.1.10</version> </dependency> |
azkaban-web-server 邮件配置遭遇Connecting to SMTP server failed
星期三, 六月 27th, 2018 | Database, JAVA-and-J2EE, 大数据 | 2 Comments
azkaban-web-server 邮件配置遭遇Connecting to SMTP server failed
0.先说下使用的版本azkaban-web-server-3.45.0-10使用jdk1.8.151编译
1.启用azkaban的邮件配置在 azkaban.properties中定义发送邮箱
mail.sender=xx@qq.com mail.host=smtp.exmail.qq.com mail.user=xx@qq.com mail.port=465 mail.password=xxxxxx #[email protected] #[email protected] mail.tls=true |
2.配置job文件里配置接收邮箱地址
#file.job type=command command=sh /usr/local/bg/files/test.sh working.dir=/usr/local/bg/files/job/working notify.emails=xx@qq.com failure.emails=xx@qq.com success.emails=xx@qq.com |
3.遭遇错误如下
ERROR [EmailMessage] [Azkaban] Connecting to SMTP server failed, attempt: 0 javax.mail.MessagingException: Exception reading response; nested exception is: java.net.SocketTimeoutException: Read timed out at com.sun.mail.smtp.SMTPTransport.readServerResponse(SMTPTransport.java:2210) at com.sun.mail.smtp.SMTPTransport.openServer(SMTPTransport.java:1950) at com.sun.mail.smtp.SMTPTransport.protocolConnect(SMTPTransport.java:642) at javax.mail.Service.connect(Service.java:295) at azkaban.utils.EmailMessage.connectToSMTPServer(EmailMessage.java:226) at azkaban.utils.EmailMessage.retryConnectToSMTPServer(EmailMessage.java:236) at azkaban.utils.EmailMessage.sendEmail(EmailMessage.java:219) at azkaban.utils.Emailer.sendSuccessEmail(Emailer.java:231) |
4.解决方式需要修改源码并重新编译之 重新编译azkaban.utils.EmailMessage即可,
› Continue reading
支持emoji图标直接存储到数据库,更改MySQL数据库的编码为utf8mb4
星期一, 十月 23rd, 2017 | Database, JAVA-and-J2EE | 一条评论
随着emoji的频繁使用,对接微信后会带名字的emoji的很多,现在都需要支持.
utf-8编码可能2个字节、3个字节、4个字节的字符,但是MySQL的utf8编码只支持3字节的数据,而移动端的表情数据是4个字节的字符。
如果直接往采用utf-8编码的数据库中插入表情数据,java程序中将报SQL异常:
1 2 3 4 5 6 7 8 9 | java.sql.SQLException: Incorrect string value: ‘\xF0\x9F\x92\x94’ for column ‘name’ at row 1 at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1073) at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3593) at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3525) at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1986) at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2140) at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2620) at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1662) at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1581) |
可以对4字节的字符进行编码存储,然后取出来的时候,再进行解码。但是这样做会使得任何使用该字符的地方都要进行编码与解码。
utf8mb4编码是utf8编码的超集,兼容utf8,并且能存储4字节的表情字符。
采用utf8mb4编码的好处是:存储与获取数据的时候,不用再考虑表情字符的编码与解码问题。
更改数据库的编码为utf8mb4:
1. MySQL的版本
utf8mb4的最低mysql版本支持版本为5.5.3+,若不是,请升级到较新版本。
2. MySQL驱动
5.1.34可用,最低不能低于5.1.13
3.修改MySQL配置文件
my.cnf一般在/etc/my.cnf位置。找到后请在以下三部分里添加如下内容:
1 2 3 4 5 6 7 8 9 10 | [mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci init_connect='SET NAMES utf8mb4' [client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 |
4. 重启数据库,检查变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%'; Variable_name Value character_set_client utf8mb4 character_set_connection utf8mb4 character_set_database utf8mb4 character_set_filesystem binary character_set_results utf8mb4 character_set_server utf8mb4 character_set_system utf8 collation_connection utf8mb4_unicode_ci collation_database utf8mb4_unicode_ci collation_server utf8mb4_unicode_ci collation_connection 、collation_database 、collation_server是什么没关系。 但必须保证 系统变量 描述 character_set_client (客户端来源数据使用的字符集) character_set_connection (连接层字符集) character_set_database (当前选中数据库的默认字符集) character_set_results (查询结果字符集) character_set_server (默认的内部操作字符集) 这几个变量必须是utf8mb4。 |
5. 数据库连接的配置
数据库连接参数中:
characterEncoding=utf8会被自动识别为utf8mb4,也可以不加这个参数,会自动检测。
而autoReconnect=true是必须加上的。
6. 将数据库和已经建好的表也转换成utf8mb4
更改数据库编码:ALTER DATABASE xxdb CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
更改表编码:ALTER TABLE TABLE_NAME CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
如有必要,还可以更改列的编码
linux每天定时备份MySQL数据库并删除五天前的备份文件
星期五, 三月 17th, 2017 | Database, JAVA-and-J2EE | 没有评论
MYSQL定期备份常用脚本如下:
1. mkdir -p /bak/mysqlbak 2.vi bakmysql.sh 内容如下 #!/bin/bash # Name:bakmysql.sh # This is a ShellScript For Auto DB Backup and Delete old Backup # backupdir=/bak/mysqlbak time=` date +%Y%m%d%H ` /usr/local/webserver/mysql/bin/mysqldump -root-pxxx -S /tmp/mysql.sock xx| gzip > $backupdir/xx_$time.sql.gz # find $backupdir -name "xx_*.sql.gz" -type f -mtime +5 -exec rm {} \; > /dev/null 2>&1 |
MySQL表类型和存储引擎的修改遭遇版本不一致
星期五, 七月 25th, 2014 | Database, JAVA-and-J2EE | 没有评论
使用的是老版本的mysql客户端Navicate 8 ,mysql 服务端用的是mysql5.6的版本,在修改版本引擎的时候出现版本不对;
mysql error ‘TYPE=MyISAM’
解决办法:
Replace
TYPE=MyISAM
with
ENGINE=MyISAM
The problem was “TYPE=MyISAM” which should be “ENGINE=MyISAM” as per MySQL version updates – a simple search / replace has fix it.
附 修改表引擎sql:alter table db.user engine =MyISAM;
mysqldump导出部分数据和insert into 复制部分数据
星期二, 六月 10th, 2014 | Database, linux | 没有评论
今天想导出部分数据找了半天终于找到对应的几个方法
首先看下字符集,省的导出的时候是乱码
1.用命令
mysql> SHOW VARIABLES LIKE "character_set%"; |
根据对应的字符集value决定采用导出字符latin1 还是utf8
2.采用 –where的方式导出
mysqldump -uroot -p123456 --default-character-set=latin1 i5a6 i5a6_data --where=" id < 100" > bki5a6.sql |
3.采用创建新表结构和原来表相同复制部分数据的形式再全部导出新表数据即可
INSERT INTO Table2(field1,field2,...) SELECT value1,value2,... FROM Table1 |
涉及更多 mysql备份导入导出说明(二进制导出等) 参见 ://www.pomelolee.com/1088.html
完毕,感觉采用mysqldump 导出的时候更省事,流着以后用的时候好直接翻阅
mysql备份导入导出说明和对应的shell脚本
星期六, 十二月 22nd, 2012 | Database | 没有评论
1.导出整个数据库(–hex-blob 为有blob数据做的,防止乱码和导入失败用)
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
1 | mysqldump -u root -p --default-character-set=gbk --hex-blob i5a6 > i5a6.sql |
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
1 | mysqldump -u root -p i5a6 users> i5a6.sql |
3.导出一个数据库结构
1 | mysqldump -u root -p -d --add-drop-table i5a6 >d:/i5a6.sql |
-d 没有数据 –add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
1 | mysql>source d:/i5a6.sql |
MySQL Installer 5.5.29在win7下安装失败解决
星期六, 十二月 22nd, 2012 | Database | 没有评论
今天下载了最新版的mysql,安装的时候遭遇 Last error: unable to configure service,在最后配置的时候出错.
几次三番都是一样,端口3306肯定是没有占用,系统也从来没有装过mysql,很是诡异.
最终的解决之法居然是换个安装目录,本人前次是安装在 D:/soft/db换成D:/db下居然好了,难道和/s有关???
如下步骤成功安装。
1.首先卸载没有成功安装的MYSQL的一系列东东
2.清理下注册表,cmd下运行 regedit 后-F3-搜索你的安装路径,我的是:D:/soft/db.删除所有能找到的键或者键值.(蛮多的)
3.使用netstat -na 确保3306端口未被占用,换个端口应该也行,我的3306没有用
4.更换安装目录为D:/db

Search
相关文章
热门文章
最新文章
文章分类
- ajax (10)
- algorithm-learn (3)
- Android (6)
- as (3)
- computer (86)
- Database (30)
- disucz (4)
- enterprise (1)
- erlang (2)
- flash (5)
- golang (3)
- html5 (18)
- ios (4)
- JAVA-and-J2EE (186)
- linux (144)
- mac (10)
- movie-music (11)
- pagemaker (36)
- php (50)
- spring-boot (2)
- Synology群晖 (2)
- Uncategorized (6)
- unity (1)
- webgame (15)
- wordpress (33)
- work-other (2)
- 低代码 (1)
- 体味生活 (40)
- 前端 (21)
- 大数据 (8)
- 游戏开发 (9)
- 爱上海 (19)
- 读书 (4)
- 软件 (3)